

This blog article is a culmination of my years of experience in the networking and computing worlds. Over those years, where I began as a bench and field technician, I have had a number of classes that my employers sent me to to teach troubleshooting skills. Usually termed with the words “logical troubleshooting” or something similar, these classes focused on how to troubleshoot certain products, or processes associated with certain products, and their functions in the network. It was clear to me then, and it remains clear to me now, that networking and computing are very closely related. Most networking devices (switches/routers, etc.) are themselves really built for purpose computers.
My goal in this article is to share my troubleshooting experience that I have developed over my career. You, the reader/student, have to digest this information, take from it what works for you and your mind, organize it into a process that helps you to troubleshoot more effectively, more completely, with a higher level of positive impact and success.
A side note: I often travel with a “go bag” full of my favorite troubleshooting tools. You can find that list here.
One of the things that drove me crazy (and still does), and I mean crazy – like I can’t sleep well – is when I can’t fix something right the first time. When I worked on a bench, this meant items would be returned after being “repaired”. When I was in Field Service operations this was termed “call backs”. If anything required more than swing at troubleshooting and fixing a problem, it meant that I had failed, that everything I had done in the first swing was probably wrong. I took this as not only a personal failure, but also a failure in whatever troubleshooting process I had used. If you are like me in this regard, then I understand your desire to be better, and why you are probably reading this article. If you are not like me in this regard, I am very jealous, and I am so pleased that even though you aren’t as sensitive to the issue of call-backs or returns, you have decided to take on this article anyway.
All that said, the overall process I discuss should be applicable to any networking or computing problem in general. Obviously, I cannot go into specific products and so forth. For that I leave it to you the reader/student to adapt what is provided to your specific product, or network, or function. However, I just watched a video on YouTube about troubleshooting and after investing nearly 30 minutes, I really had not learned anything. So I want to provide some detail as to the troubleshooting steps in several scenarios that you can take away, modify, customize, and then use them in your job function.
What is “Troubleshooting”?
Let’s start with defining what troubleshooting is, and perhaps more importantly, what it is not.
I have always said this in my hands-on courses: Power Cycling and/or rebooting is NOT troubleshooting. “But it fixed the problem!” you say. If that is true, then tell me what the cause of the problem was that the reboot or power cycle fixed? I’ll bet most people could not answer the question without guessing. To be transparent, I would not be able to say what caused the problem either. I could guess, but I really would not know. The reason for not being able to say specifically is that troubleshooting was not done. There is no “evidence” of what was wrong. All we know is that we were able to apparently fix the problem…or were we? A terrible fact in the communications and computing industry is this process of rebooting/power cycling has become so entrenched that customers do this by rote, and they automatically say to support, when the problem recurs, that they already rebooted. Worse yet, if the reboot fixes the problem every time, nothing is getting truly fixed. You could even say that, in some cases, by continually reboot or restarting a given system that we are masking the issue.
Therefore, part of troubleshooting is a forensic gathering of evidence. One has to be extremely curious. Similar to the Crime Scene Investigator, we need to develop a rigorous, comprehensive process to gathering information. Then we need to process the results of information gathering to home in on where the source of the problem is. If you are not inspired by the challenge, if you don’t have the curiosity to work the process, you probably aren’t cut out to troubleshoot and correct problems. I doubt there are many of you who do not have the needed curiosity, and therefore the inspiration to find and solve the problem.
High Level Troubleshooting Approach and State of Mind
The following are the critical but general things that I always do in order to position my more detailed troubleshooting process in the best possible way. These overarching approaches are always in play for me.
1. Have a checklist, or step-by-step process predefined that will define your direction. Start with a physical printed checklist until that checklist becomes indelibly stamped in your brain – memorized word for word.
2. Follow a layered model approach – if it is networking the layered model is well known, but to no surprise, all computer based systems are layered as well. I really don’t care what you call this layered model
3. Get access to the failing or troublesome network/system as quickly as possible, and keep others away to avoid contamination of your “crime scene”.
4. Begin isolation or narrowing of the cause of the problem by using either a bottom up, top down, or the half split method. Bottom up and Top down are relatively easy concepts: you start thinking of the layered model and then work your way one way or the other. I tend to lean on bottom up here. Starting at the Physical layer: Are there wiring or fiber or radio issues? Bit errors? Then up to Datalink, etc. The half split method works as well. An example of what I mean here can be described against the layered model: start in the middle, checking operation, then move half way up or half way down, checking operation, and keep splitting in half until you have eliminated what is not the issue and are hopefully homing in of where the problem actually is. I make this sound a lot easier than it really is. Don’t be afraid to go back to square one, iterating this narrowing process.
5. Be in a data/facts/evidence gathering mode immediately, and keep copious notes/screen shots/downloads/etc.
6. Keep in mind that evidence something is working is as important as evidence something is not working properly.
State of Mind: Theory vs. Reality
Never jump to quick conclusions. Here is why: if your thoughts have postulated a conclusion, the human in you starts two twist the facts to align to the already guessed conclusion or the theory. The reason for this is we have been taught all through primary school and higher education to be “right”, therefore you want to be right. The network or the system does not care about being right or wrong. The best thing you can do is steer clear of this entire human problem. Stick to the reality:
- what happened?
- how did it happen?
- when did it happen?
- what trails did the event leave?
Here is another state of mind to avoid: if a little voice inside your head says “I’ve seen this before” or “I know what this is.” immediately stop yourself. While it is possible that the problem you are solving has been seen before, you have to squelch these thoughts for the same reason the early conclusion is a mistake. Gather the evidence, follow the evidence. Prove it first. More often than not, these thoughts will lead you down a false path, and you could end up making something worse because you start to take unnecessary corrective actions.
“Just the facts, Ma’am.” is a phrase made famous by Jack Webb (check out this biography: https://www.amazon.com/Just-Facts-MaAm-Authorized-Biography/dp/092976529X ) who played Sergeant Joe Friday on Dragnet (an American radio, television, and motion-picture series) where the success in solving various police cases was always solved through a consistent methodology and evidence gathering process. So stick to the facts, stick to reality, and follow them to the source of the problem.
Baselines
There is a very important concept that will greatly impact your effectiveness in troubleshooting. The concept is captured in a word: Baselines. What are baselines in this context? The answer is that baselines are “normals”. Every network is slightly different, even though they are comprised of the same things (like interfaces, routers, switches, and other equipment). Therefore what is “normal” on one network may be slightly different on another network. Each network will have its own unique quirks and performance criteria. Each will have its own baselines.
To be efficient you have to measure, test, and baseline your network. You have to know what is good, what is normal. After all, if you don’t know what normal is, how on earth will you recognize when something is wrong or abnormal. Keep in mind this normal will vary hour to hour, day to day. Don’t be fooled into thinking that a baseline you measure today will be the same down the road. You have to know your system or network. Here are some examples of baselines:
• 50ms average ping response time between 10.0.125.121 and 10.0.124.65
• Average TCP connections between server 10.0.0.1 and 10.0.10.1 is 16
• 4 percent packet loss on Wi-Fi segment 172.16.10.0 with 38 percent load
• Application APACHE generates 18 Mbps of traffic during account queries
• The average amount of bandwidth on interface gig1/1/1 is 480Mb/s
These are just examples, and you should not use any of them in your network. That said, could you tell me some of these baselines as they apply to your network? I hope you get the idea.
Many times you can get baseline information from queries or show commands on routers and switches, or output from management systems. One of my favorite tools for baselining is Wireshark. Most of the tools Wireshark offers are in the Statistics menu, but I will point out a few helpful ones.
First, capture file properties:
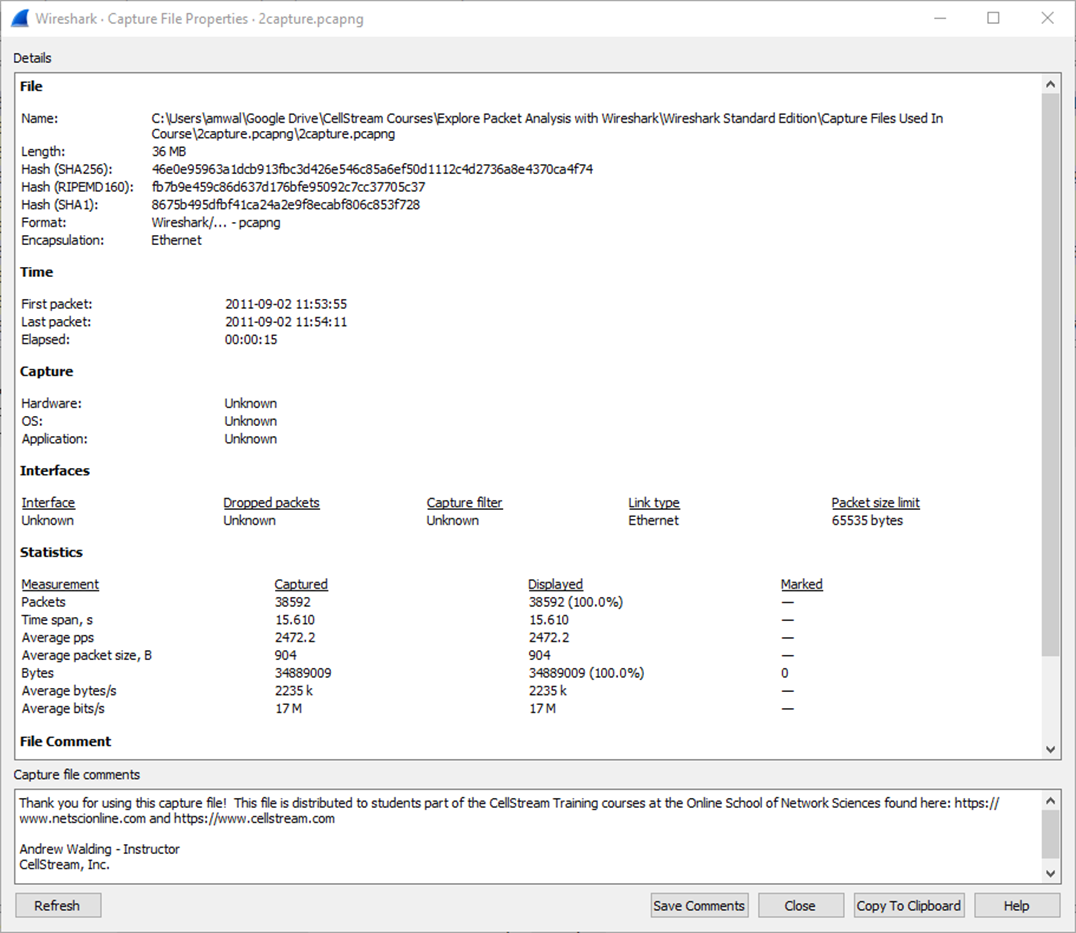
You can see bandwidth average packets per second and more. You should use this to baseline networks but also applications. For example, how much bandwidth does it actually take to watch a YouTube video in HD? or in 720p? How about Netflix or Amazon? Are they the same? Different? These are baselines you have to know, have to know how to attain, and have for your records.
Another is Protocol Hierarchy:
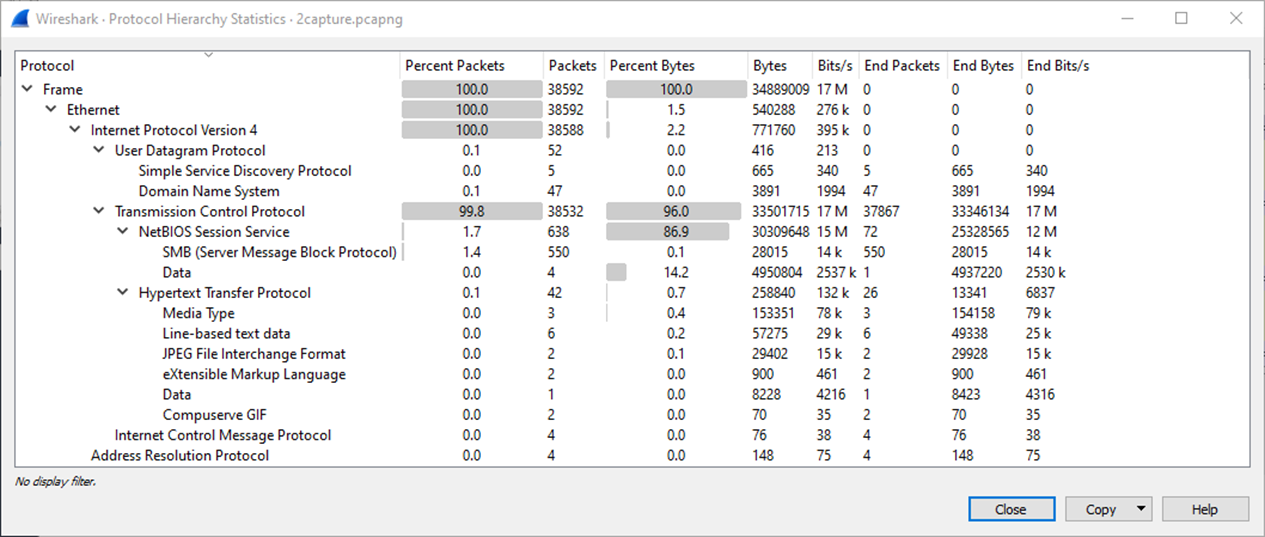
This helps get a good feel for types of traffic and the layers of protocols on the network.
And another is the I/O graph:
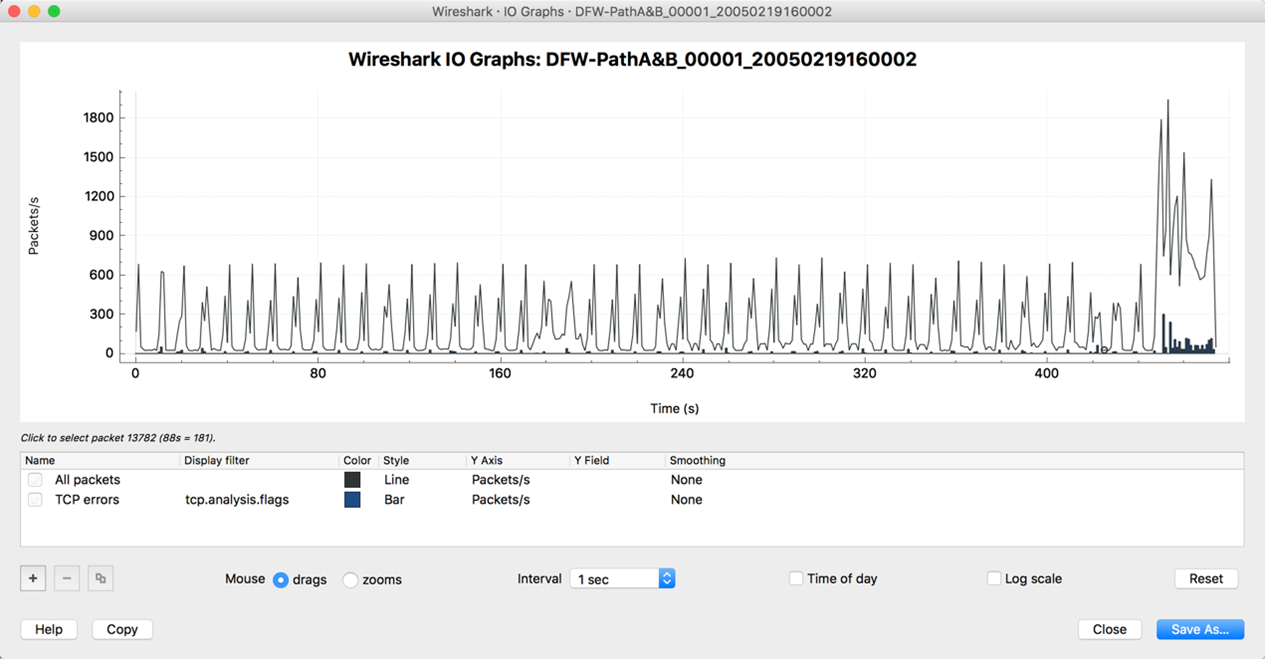
A great way to visualize the traffic. Frankly, this subject is a deep pond with the ability to add filters and the like, but I will leave the concept there.
Another aspect of baselining is the use of tools that do monitoring/network management. Those who know me know I like Observium as an example. You can see my full list of network management tools here: https://www.cellstream.com/reference-reading/tipsandtricks/330-a-list-of-network-monitoring-tools-for-network-and-system-administrators
I always like to have a solid diagram of the network involved. So many people forget this part of baselining. So few networks I work with even have such diagrams, at least not accurate ones. There is a tool I often use to create them called draw.io (https://www.diagrams.net), again fully cross platform, but any tool/drawing is better than none.
I always like to grab and store the configurations of routers/switches/network elements, and I almost always put these in CherryTree. I think of these as my “golden configs” – having these offline and available really helps me to note whether something changed. It also helps me to write “Methods of Procedure” or MOP’s when something needs to be changed. Since we are on the subject of tracking changes, be sure to document any changes with MOP’s, and keep these on hand, readily available, for evidence gathering. I consider these changes to be part of the baselining of a network, a little like your medical history if you are suddenly not feeling well.
Ask Questions
Never never assume you know an answer. Always ask the question. Sometimes it is asking a user or a network administrator or a colleague. Sometimes it is asking yourself. Here are example questions that must always be asked, often iteratively:
- What changed?
- When did it change?
- What are the timelines?
- What is normal?
- Where is the DNS?
- Where is the DHCP Server?
- Where is the Default Gateway?
- Is there NAT?
- What are the IP Addresses?
- What are the VLANs?
- What are the network components?
And the questions can go on and on. What questions should I have added? Comment below.
Tools of the Troubleshooting Trade
As you mentally digest the overarching concepts, lets talk about troubleshooting tools. Tool discussion is one of those things you do not see or hear about in many troubleshooting articles. I wonder why? Now, I have already mentioned a couple, and I will not repeat them. To me, this type of guidance is critical. We will stay fairly general here, yet I will drop a few suggestions (keep in mind I am not sponsored by any of the tools mentioned as examples). You have to have a set of tools you are comfortable with and that you can use quickly and reliably.
Often in the face of outages or failures, time is of the essence. People above you in the chain of command, or customers, will be impatient for you to get the system or network running again, and worry about what caused the failure later. With regards to tools, you do not want to be causing delays while you try to find of set up tools.
It is critical, in my opinion, to be fluent in at least three major OS platforms. For me that means MS Windows, Apple MAC OS, and Debian Linux. You should pick your three, or more, and make sure you can find tools that work “cross platform”, or find tools that work the same way to minimize impact to you. Further you need to have the appropriate hardware as well. An example is packet sniffing: do you have full duplex taps, Ethernet cables and such? I always have a go bag full of the equipment I need, and you should build one as well. I will leave the hardware aspect there as there are so many variations. However, if you want to add comments below of what you need/use in your function to expand this article, please do so. Everyone can then benefit from such contribution.
Evidence gathering is paramount. I strongly suggest using a hierarchical notes tool that has the ability to insert images and files quickly and easily. My personal favorite is Cherry Tree, although there are a number of similar tools. I find it just provides everything I need to organize my evidence. It is cross platform, and it is flexible and adjusts as I work, so I can move evidence around and relate one piece of information with another.
Screen shots are critical and you often have to be quick. If you are accessing systems using a browser, I suggest Vivaldi. It is Chromium based, cross platform, and has built in snipping. Fast, and I love that. Sometimes evidence is fleeting. I also use Techsmith’s Snagit on my Windows and MAC platforms, and then different snipping tools on other Linux systems (I like Flameshot). The bottom line here is use a tool you are comfortable with and get good with the tool.
Right behind screen shots is the ability to do screen recordings of what you are doing. I have used this more and more lately. Many of the screen shot tools now do screen recording, so exploit those capabilities or change to a tool that does both.
For network traffic/packet capture – there is only one answer for me: Wireshark – and it is cross platform as well. Just make sure you customize it so you are fast. You can do this with Wireshark’s custom profiles. You can read more on this feature and exploit the capability here: https://www.cellstream.com/resources/wireshark-profiles-repository
Make sure you have a dedicated file space ready and available. I tend to use my desktop in the heat of the troubleshooting process and them move everything afterward. That way my desktop is ready for the next fire fight. I have seen others use network drives and such, but I always find that to be risky and sometimes access can get in the way of speed. The key here is to be efficient and clean up after yourself. Don’t forget that dumping files into your notes tool works great here as well.
One thing I like to have in my go bag is a Raspberry Pi with some tools pre-loaded on it (you can get the system I have here – this is our Amazon Associate link where we get a small cut if you buy it from this link). Another great OS to have on a stand alone laptop is Kali Linux as it also comes preloaded with a ton of tools – sure they are Pen Testing focused, but so many can be used for troubleshooting as well as baselining your network. A quick short list of my commonly used tools:
- Wireshark: https://www.wireshark.org
- Nmap: https://nmap.org
- Ansible Automation: https://www.ansible.com
- Paris: https://www.paris-traceroute.net and Dublin https://dublin-traceroute.net/README.md Traceroute
- SmokePing: https://oss.oetiker.ch/smokeping/
- iperf: https://iperf.fr
- Logging: https://logz.io
- Netflow: https://www.paessler.com/netflow_monitoring?msclkid=ff6927834875140866ec45dae8da7988&utm_source=bing&utm_medium=cpc&utm_campaign=USA_EN_Search-nonBrand_exact_1&utm_term=netflow&utm_content=netflow
- I have a list of the hardware that I use when troubleshooting here: https://www.cellstream.com/2024/10/28/the-products-we-use/
- I have a full list of Network Monitoring tools here: https://www.cellstream.com/reference-reading/tipsandtricks/330-a-list-of-network-monitoring-tools-for-network-and-system-administrators
From here, once again, there are thousands of tools possibilities depending on what you are troubleshooting. Please feel free to add your favorite tools and why/what you use them in the comments.
Detailed Actions and Steps
Time to get into some details. We understand the big picture, we have some possible tools, and now we need some critical steps, vital details, and important checklists we can take in our troubleshooting process. I think it is only appropriate to provide a couple of examples where I practice what I preach above.
Remember – at each step on these checklists, I would expect to be creating evidence, recording what I found.
Example Case #1 – General Network Issue
I wanted to start with a generic checklist that we can then hone as we take on different example cases. In this case, lets say someone has sent a packet capture and we need to find out what is wrong generically. The difficult issue here is we have no baseline (unless it is provided).
- General Starting Point
- Look at the Wireshark Expert Info/Analysis
- Look at the Statistics and I/O Graphs
- Check long Delta Times
- Is the network congested? On the local link? On the access link?
- Layer 2:
- ARP
- STP
- VLAN
- Layer 3:
- Fragmentation
- ICMP
- IP QoS
- Check DNS operation
- Check NAT is working as expected
- Layer 4 (also see detailed TCP checklist below):
- Check tcp.analysis.flags
- Check TCP 3-way Handshake
- Check TCP Sequence Analysis
- Number of sockets and other statistics
- Layer 5: HTTPS/FTP/SSH etc.
What would you add here? Please comment, but also look at the other cases below.
Example Case #2 – Network is Slow – Focusing on the TCP Protocol
TCP is an end-to-end protocol. When something is slow, it means that the network is generally working. So I like to start at that first layer where we are end-to-end. So let’s talk about TCP. Now TCP is hard. Remember this is a checklist/tip list. It is not a lesson on TCP. We assume you have a packet capture and a knowledge of how the TCP protocol works.
- Are there any big obvious issues: My favorite filter: “tcp.analysis.flags”
- tcp.analysis.retransmission
- tcp.analysis.fast_retransmission
- tcp.analysis.lost_segment
- tcp.analysis.duplicate_ack
- tcp.analysis.out_of_order
- tcp.analysis.window_full
- tcp.analysis.zero_window
- The TCP Handshake
- Look closely at the three-way handshake
- Ensure MSS sizes are good
- Watch for small Window sizes
- Watch Round Trip Times
- Look to see if SACK is enabled
- The only valid responses to SYN is either SYN-ACK or RST
- Filter on port (application) numbers, not the protocols (port 21 vs. ftp, or port 80 vs. http), for example “tcp.port==80”
- Use the Expert tools for guidance not pin-point accuracy
- Build profiles to match the area you are troubleshooting
- Recolor packets in conversations to compare different chats
- Check TCP Preferences
- Enable TCP Conversation Timestamps
- Use the IO Graphs, click through it to rapidly get to suspect packets/areas
- Be looking for patterns
- If Sequence is all caught up, the next packet in the conversation is the source of application delay; look at delta times
- Are you actual troubleshooting proxies, load balancers, etc.
- Turn off relative sequence numbers
- Watch for port number reuse (should be NPAT not just NAT)
Example Case #3 – Voice over IP Troubleshooting
I cannot stress the importance in this area of having a good set of VoIP profiles for Wireshark. The link was earlier in the article. Notice here, I almost use a bottom up approach, still checking things like Ethernet and IP layers before delving into the VoIP layers with SIP/SDP and RTP/RTCP. Remember this is a checklist/tip list. It is not a lesson on VoIP. We assume you have a packet capture and a knowledge of how VoIP protocols work.
- Look at the Wireshark Expert Info/Analysis
- Look at the Statistics and I/O Graphs
- Check long Delta Times
- Layer 2: ARP, STP, VLAN
- Layer 3:
- Fragmentation
- ICMP
- IP QoS
- Check DNS operation
- NAT – is it in play? Is it working properly?
- SIP/SDP
- Statistics
- Errors
- Port Numbers
- Communications Ladder – the process
- RTP/RTCP
- 20 msec delta times
- Sequence Numbers
- Statistics
- Use the built in player to listen for things like echo, pops, buzzes, etc.
Example Case #4 – Fiber Optic Troubleshooting
We appeared to have a fiber failure and when we went to a second dark fiber, we had no joy. I know what you are thinking, it could not have been the fiber. It must be the SFP’s or the interface on the switch. This is a perfect example of how jumping to a conclusion with not enough evidence can do messing with your troubleshooting mind.
- Isolation of the problem: no conclusion, let’s first replace the “failed fiber” with a known good jump cable and loop it back to isolate the fiber from the interfaces.
- If that is good, we have to now suspect the fiber. Run testing on the fiber.
- Verify that fibers are properly labeled.
- If testing is being done ensure the testing is within distance specifications.
- If that is indeed bad we need to repeat the process on the second fiber that also failed.
- If it fails, try a third fiber.
- If that fails, you need to verify that you are actually testing the same fiber at each end.
- Send signal on a fiber, and have the other end test all fibers to ensure fiber marking is correct.
- Lastly, run actual test traffic on the working fiber to test throughput.
Example Case #5 – Wi-Fi/WLAN Troubleshooting
Troubleshooting wireless LAN’s and Wi-Fi is discussed heavily all over YouTube and the web. But I have developed my own process for this, that has rarely let me down. This process follows a not so conventional approach, as you will see.
- 1. Always ensure the latest firmware/software/device drivers are in play. There is an unfortunate problem in the industry: the rush to release products does not balance with the complexity of networking: Never enough testing. which leads to performance and security issues. The result is a constant stream of software and driver updates. Even with brand new products, the first thing that happens when you turn the product on, is you have to download new software/firmware. Therefore, a critical step in troubleshooting is to ensure all the latest firmware/drivers/software is in place. That may eliminate problems – troubleshooting complete!
- Try to determine if the problem is new or pre-existing.
- If the problem is new – we can quickly scan for interference or overcrowding. Since interference and overcrowding are issues that tend to evolve, we must constantly check them. Performing these verifications allows us to adjust channels or better place AP’s. Then make adjustments and retest.
- If the problem is pre-existing – time to go back to square one. Perform a site survey with Wi-Fi scanning and RF scanning tools, and determine the best location(s) for AP(s), the sources of interference, and/or proper channelization. Make adjustments and retest.
- Eliminate Interference and channel balance issues.
- You need a spectrum analyzer for the RF (I like the Wi-Spy and Channalyzer products, but there are many options here)
- You need a good Wi-Fi scanner/process (for Windows I like Win-Fi, but so many others are perfectly fine – it is difficult to find cross platform stuff here).
- If all the above is good, you have to be down to some kind of MAC Layer issue, so it is time to perform a Wi-Fi network packet capture and analyze – meaning you must be in monitor mode, so I like using Linux as my go to OS here, but MAC is good too. Windows – well it just does not work well. See my article here for more details: https://www.cellstream.com/reference-reading/tipsandtricks/560-monitor-mode-in-windows-at-last
Some Final Thoughts
I hope this article has helped those of you who needed troubleshooting guidance, or recommendations, or even just a refresher on much of what you knew already. I wanted to catch a few loose ends in this last part of the article.
One important thing is to remember to iterate any process you develop/use. Stay flexible, bending with the technology as it evolves, and being willing to learn new tools and methods. One thing we can all say about Networking and Computing technology is that it is always evolving, sometimes making giant leaps forward, and you need to welcome those changes as they happen.
Another important loose end is that, if you are like me, you always learn something whenever you travel down a troubleshooting event. I always like to do a debrief with my team, my client, or my customer after the failure or issue is resolved. I try to rigorously answer the following eight questions as a group and record our answers (I suggest having a template document for this and customizing these questions to better fit your environment):
- Can we identify the root cause?
- Is this a repeat problem? If so, what did we do wrong the first time?
- Could that root cause have been prevented? If so, how?
- Is there any possibility this could happen again? If so, what should we do to avoid the issue?
- How could we have found the problem faster or earlier or more directly?
- What, if anything, could we have dome better to mitigate or at least have minimized the problem in the first place?
- What have we learned from the event?
- Is there anything we need to do differently going forward?
I would love to hear some of your tips and thoughts, so please expand the discussion below. I thank those that share in advance.