
What exactly is the purpose of the IP ID field? This is actually a great question. While many have tried to answer the question in various articles on the Internet, I thought the question deserved a clear answer to the question. RFC 6864 updated RFC’s 791, 1122, and 2003 to clarify the definition of the IPv4 ID field:
In IPv4, the Identification (ID) field is a 16-bit value that is unique for every datagram for a given source address, destination address, and protocol, such that it does not repeat within the maximum datagram lifetime (MDL) [RFC791] [RFC1122]. As currently specified, all datagrams between a source and destination of a given protocol must have unique IPv4 ID values over a period of this MDL, which is typically interpreted as two minutes and is related to the recommended reassembly timeout [RFC1122]. This uniqueness is currently specified as for all datagrams, regardless of fragmentation settings.
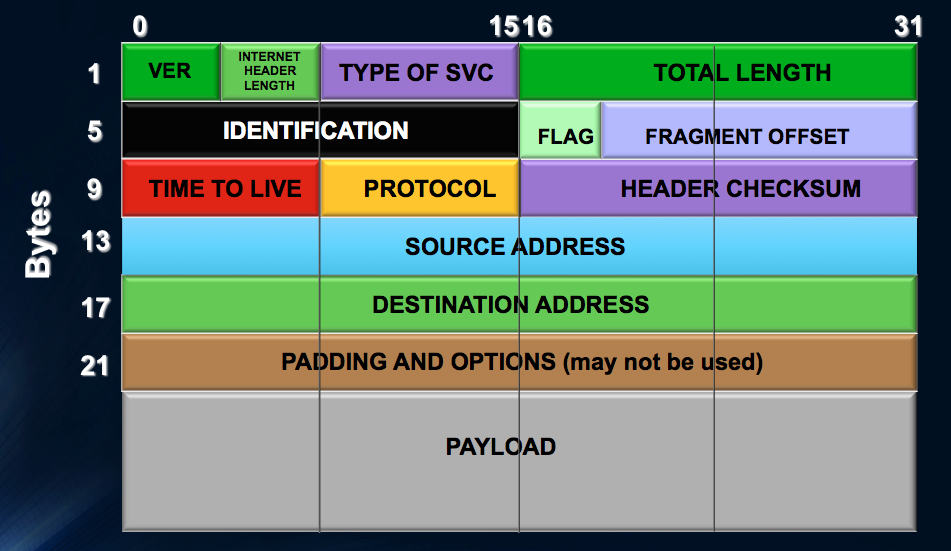
Here is a graphical representation of the IPv4 header:
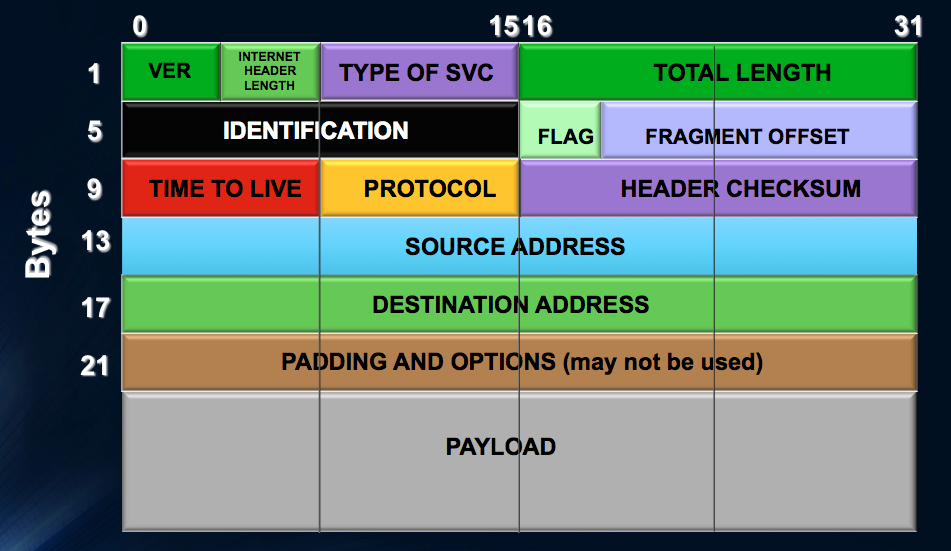
IP ID Field in Fragmentation
The first answer defining the IP ID field has to do with IP packet fragmentation. RFC 6864 clarifies that the primary purpose of the ID Field is in support of fragmentation and reassembly. In IPv4, datagram size is limited by the Total Length field with is 16 bits. Thus 2^16 is 65535 bytes. However, we know that Ethernet, for example, uses a maximum transmission unit size of 1500 bytes. Usually the IP protocol stack will set the size of the IP packets to fit into their Ethernet interfaces. However, what if that packet now goes into a tunnel interface (adding additional headers) or into an interface that has a less than 1500 byte MTU? The answer is the original IP packet must be fragmented into two packets. The first packet is a maximum size and the second is whatever is left over. These two fragments travel the entire rest of their journey to the destination where they are reassembled.
But what if there were more than 2 fragments? And how does the eventual receiver perform the reassembly accurately?
The answer is to use the second 32 bit word of the IPv4 header:

The M bit as shown is the More Fragments Flag.
The D bit as shown is the Do not Fragment Flag.
The result of the fragmentation process is shown below:

On the left we see a “normal” 1500 byte IP packet (20 bytes of IPv4 header plus 1480 bytes of payload. If that packet has to enter either a tunnel or an interface with a smaller MTU (the example shows 1300 bytes), 2 fragments are created. The first fragment is 1300 bytes with a 20 byte IPv4 header plus a 1280 byte payload. Also, we see an ID of 1000 being placed into the IP ID Field, followed by the ‘more’ flag being set, followed by the offset of 0 bytes (really meaning this is the first packet of the fragmented packets).
The left over 200 bytes of the original IPv4 packet now are carried in the second fragment. The second fragment shares the same IP ID field: 1000. The receiver of the fragments knows that this fragment and the prior fragment below together. Note also the more flag is set to 0, meaning no more fragments. The offset is set to 160 – this means that its payload is offset by 160 x 8 (or 1280) bytes from the prior fragment. Therefore, if you received this packet you would know this fragment belonged to the prior fragment, and be able to unpack the payloads and reassemble them in the right order. Even if these packets were received out of order, you would be able to perform reassembly.
We can also mark IPv4 packets with the Do Not fragment flag. If this bit is set to 1, then nodes in the path that encounter the need to fragment, the packet can be discarded.
What about IPv6?
Check out these additional IPv6 Resources: |
| Our IPv6 overview course at Udemy |
| Our IPv6 Custom Profiles for Wireshark |
| Our IPv6 classes at the Online School |
Well, IPv6 requires something called Path MTU Discovery, to minimize fragmentation (if not eliminate it completely). Simply stated, this means that sending hosts must adjust packet sizes to fit in the smallest MTU on a given path to a destination. They ‘discover’ the size thanks to the ICMP error message system.
Also, IPv6 no longer has fragmentation support in the standard header! Instead, there is an extension header that contains the fragmentation information:

You can see that the main difference is the size of the IP ID field! Other than that, it works the same way.
Other Uses for the IP ID field
There have been a number of other IP ID implementations other than fragmentation and reassembly. Per RFC 6864:
-
The field has been proposed as a way to detect and remove duplicate datagrams, e.g., at congested routers (noted in Section 3.2.1.5 of [RFC1122]) or in network accelerators.
-
It has similarly been proposed for use at end hosts to reduce the impact of duplication on higher-layer protocols (e.g., additional processing in TCP or the need for application-layer duplicate suppression in UDP).
- The IPv4 ID field is used in some diagnostic tools to correlate datagrams measured at various locations along a network path. This is already insufficient in IPv6 because unfragmented datagrams lack an ID, so these tools are already being updated to avoid such reliance on the ID field.
- Atomic datagrams: these are datagrams not yet fragmented and for which must not be fragmented. (DF==1)&&(MF==0)&&(frag_offset==0).
- Non-atomic datagrams: these are datagrams either that already have been fragmented or for which fragmentation remains possible. (DF==0)||(MF==1)||(frag_offset>=0)